With zonal OCR extracts, you can define specific zones or fields in a document and use template OCR to automate what would otherwise be manual data entry. By integrating tools like TurboDoc’s API, businesses can parse specific data, streamline their workflow, and take document management to the next level.
What is Zonal OCR?
Zonal OCR (sometimes called OCR zoning or zone OCR) is a specialized method of optical character recognition that focuses on extracting information from specific zones within a document. Unlike a standard OCR system that converts an entire page into plain text, zonal OCR extracts only the specific data fields you define.
For example:
- Extracting invoice numbers from the top-right corner of an invoice PDF.
- Pulling customer names from a designated area in a form.
- Capturing dates or totals from a semi-structured receipt.
This approach makes zonal OCR software extremely effective for document management and automation workflows where precision is critical.
Automate document processing with TurboDoc
Recognize invoices, contracts, and forms in seconds. No manual work or errors.
Try for free!

Zonal OCR vs. Traditional OCR
Here’s a quick comparison to illustrate the difference:
💡 Think of traditional OCR as a “scan-to-text” tool, while zonal OCR works more like a “data extraction engine.”
How Zonal OCR Software Works
A zonal optical character recognition system goes one step further than full-page OCR. Instead of converting everything into plain text, it focuses on data fields from a scanned document, extracting only the specific data points you need. This makes zonal OCR works best when documents have the same layout and repeated fields that need to be parsed.

With advanced zonal OCR solutions, companies can automate typical manual data entry accuracy challenges and improve speed and accuracy in document workflows.
OCR Zones and Data Fields
The core idea is simple: you define zones in documents and sets where OCR extracts text at specific locations. These zones act as data fields that map to relevant information.
✅ Examples of data from documents:
- Extracting an invoice number from the top-right corner of a PDF document.
- Parsing customer IDs from paper documents with the same structure and hierarchy.
- Capturing totals from semi-structured documents like receipts.
💡 Unlike traditional OCR, which extracts an entire page, zonal OCR allows you to precisely extract the data you want.
Creating OCR Templates
Template-based OCR is at the heart of zonal processing. You create templates by drawing zones on documents, and those zones in documents are applied across multiple files with the same layout.
🔧 With a simple zonal OCR system, setting up a template might look like this:
- Upload a PDF document.
- Draw a box (zone) around the field you want to extract.
- Assign a label (e.g., Invoice Number).
- Save the template.
- Run it across a batch of similar documents.
As a result, data is extracted automatically from all files, replacing manual data entry.
Automate document processing with TurboDoc
Recognize invoices, contracts, and forms in seconds. No manual work or errors.
Try for free!
Dynamic OCR vs. Regular OCR
- Regular OCR extracts everything into plain text. It’s good for digitizing archives but not for automation.
- Template-based OCR works well when documents follow a fixed structure.
- Dynamic OCR (like in TurboDoc) adapts to slight layout variations and still extracts relevant data.
Here’s a quick comparison:
How Zonal OCR Handles Scanned Documents
Zonal OCR extracts text and data fields from a scanned PDF with high OCR accuracy, provided the OCR engine can handle document quality.
📌 Key points:
- Works best with documents with the same layout.
- Can extract sequential data (e.g., line items in invoices).
- Supports different OCR capabilities depending on the software.
- OCR is easy to work with when using a modern API like TurboDoc.
👉 With TurboDoc’s OCR processing, businesses can parse specific data from PDFs or semi-structured files and integrate results directly into their workflows.
Automate document processing with TurboDoc
Recognize invoices, contracts, and forms in seconds. No manual work or errors.
Try for free!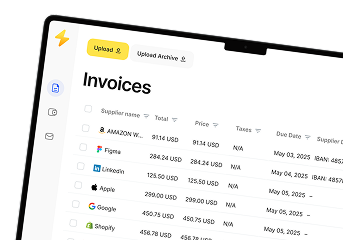
Applications of Zonal OCR
Zonal OCR can be used across a wide range of industries where precision and automation matter. Since OCR goes one step beyond simple digitization, it allows businesses to capture data fields that can be found in predictable places, automate workflows, and eliminate manual entry. In many scenarios, zonal OCR is easy to set up and delivers faster ROI than traditional OCR.

Invoice Processing
Invoices are one of the most common use cases.
- OCR extracts data such as invoice numbers, totals, dates, and vendor names.
- With zonal OCR, data fields can be found in specific zones of the document.
- This reduces errors compared to manual typing and improves processing speed.
💡 TurboDoc integrates seamlessly with accounting workflows, ensuring extracted invoice data flows directly into your ERP or bookkeeping system.
Document Processing Automation
Zonal OCR can be used to handle repetitive document processing automation tasks.
- Bank statements
- Shipping labels
- Medical forms
- Legal filings
Here, OCR is best when paired with zonal OCR templates, ensuring only the relevant data is captured, structured, and sent to downstream systems.
Extracting Data from Forms and IDs
Many semi-structured documents like forms or ID cards share similar layouts.
Extracting data from semi-structured documents is simplified with zonal OCR templates.
Typical data includes:
- Name
- Date of birth
- Document number
- Expiration date
💡 TurboDoc’s API lets you define fields once and run them across thousands of similar documents.
Business Use Cases of Zonal OCR Tools
Industries where zonal OCR is easy to apply:
- Finance → automate loan or mortgage document reviews.
- Healthcare → digitize patient intake forms.
- Logistics → capture tracking IDs from shipping labels.
- Legal → extract case numbers or client references.
In each case, OCR extracts data only from the specific zones where data fields can be found, ensuring both speed and accuracy.
Automate document processing with TurboDoc
Recognize invoices, contracts, and forms in seconds. No manual work or errors.
Try for free!
Advantages of Using Zonal OCR
When businesses move from manual entry or traditional OCR to zonal OCR software, the benefits are immediate. OCR goes one step further by capturing only the data you need, turning scanned files into structured, machine-readable outputs.
Structured Data Extraction
- Zonal OCR extracts data in a structured way (JSON, XML, CSV).
- Ensures that data fields can be found and mapped to the right destination.
- Makes extracting data from semi-structured documents efficient and reliable.
💡 TurboDoc enables direct export of structured data via API, ready for integration into CRMs, ERPs, or workflow automation tools.
Accuracy and Speed Improvements
- Eliminates typical manual data entry accuracy issues.
- Zonal OCR is easy to configure and faster than full-page parsing.
- Reduces turnaround times for high-volume document processing.
📊 Accuracy comparison:
Template-Based Automation
- Uses template-based OCR to automatically capture recurring fields.
- Works best when documents with the same layout repeat (e.g., invoices, forms).
- Saves hours of repetitive work by automating fields that need to be extracted.
Scalable Document Processing
- Handles data from PDFs, scans, and even paper documents.
- Scales easily from dozens to thousands of files per day.
- Supports dynamic OCR for documents with minor layout changes.
Limitations of Zonal OCR
Static Zones vs. Dynamic OCR
Zonal OCR relies on fixed templates. If the layout changes, fields may be missed — here dynamic OCR works better.
Poor-Quality Scanned Documents
Blurry, rotated, or handwritten scans reduce OCR accuracy and make extraction unreliable.
When Regular OCR May Work Better
For full-text search, archives, or unstructured files, regular OCR is often the best option.

Zonal OCR Software and Tools
Popular Zonal OCR Tools (Docparser, Parseur, TurboDoc)
- Docparser – good for invoice parsing but rigid templates.
- Parseur – effective for emails and PDFs, strong structured data output.
- TurboDoc – combines template-based OCR and dynamic OCR, simple to set up, scalable with API.
How TurboDoc Improves Data Extraction
TurboDoc makes zonal OCR is easy by:
- Drawing zones directly on PDFs.
- Handling semi-structured documents with dynamic rules.
- Delivering structured results (JSON, CSV, XML) via API.
Why Businesses Use Zonal OCR Software
- Automates manual data entry.
- Improves accuracy and speed in workflows.
- Extracts specific data points from invoices, forms, IDs, and contracts.
- Scales from small teams to enterprise document management.
Automate document processing with TurboDoc
Recognize invoices, contracts, and forms in seconds. No manual work or errors.
Try for free!
❓ FAQ on Zonal OCR
What is a Zonal OCR?
Zonal OCR is a method of optical character recognition that extracts data from specific zones or fields in a document, instead of processing the whole page.
What is OCR zoning?
OCR zoning is the process of defining areas on a page where OCR extracts data. These zones map to fields like invoice numbers, dates, or names.
What does an OCR stand for?
OCR stands for Optical Character Recognition, the technology that converts scanned images or PDFs into machine-readable text.
What is Zonal OCR work?
Zonal OCR work refers to setting up templates, creating zones, and automating the extraction of specific data points from documents with consistent layouts.
What is the difference between Zonal OCR and Traditional OCR?
Traditional OCR → extracts all text from a page.
Zonal OCR → extracts only relevant data fields from predefined zones, making it better for automation and structured data extraction.