Understanding the difference between OCR and ICR helps businesses choose the right tool. OCR software works best with printed text, while ICR technology handles complex handwriting using AI. Solutions like TurboDoc.io combine both approaches, offering flexible OCR/ICR integration to support a wide range of document types and recognition needs.
Automate document processing with TurboDoc
Recognize invoices, contracts, and forms in seconds. No manual work or errors.
Try for free!

What is OCR (Optical Character Recognition)?
OCR is a character recognition technology that converts printed text from a scanned image or photo into editable digital data. It’s widely used in document processing to automate the extraction of information from invoices, books, and structured forms.
Traditional OCR systems rely on fixed templates and font libraries to identify characters. While highly accurate with clean printed documents, OCR struggles with handwritten content—highlighting the key difference between OCR and ICR.
In OCR vs ICR comparisons, OCR is best for printed formats, while ICR technology handles handwritten text. Many modern platforms, like TurboDoc.io, integrate both OCR and ICR to support varied document processing needs.
What is ICR (Intelligent Character Recognition)?
ICR (Intelligent Character Recognition) is an advanced form of OCR that uses machine learning to process handwritten text. Unlike traditional OCR, which handles only printed characters, ICR technology can recognize and adapt to various handwriting styles — making it ideal for unstructured inputs like forms, surveys, and medical records.
ICR systems learn from data, improving accuracy over time. They’re commonly used in industries requiring high-volume document management, especially when data is collected manually.
While often more expensive than OCR, ICR software provides superior flexibility for handwritten content. Integrated OCR/ICR solutions, like those offered by TurboDoc.io, combine the speed of OCR with the adaptability of ICR, enhancing overall intelligent document processing across diverse input types and scanners.
ICR vs OCR: Key Differences in Character Recognition Technology
To understand the difference between OCR and ICR, it’s important to compare how each technology works and where it performs best in real-world document processing. Both are forms of character recognition software, but their use cases and capabilities differ significantly.
🔍 Comparison Table: OCR vs ICR

When to Use OCR vs ICR
- Use OCR when dealing with printed invoices, receipts, books, and other structured documents.
- Use ICR for recognizing handwritten text in forms, applications, or medical records — especially when inputs vary by user.
- For mixed-content workflows (printed + handwritten), a hybrid solution is ideal.
🚀 How TurboDoc.io Combines OCR and ICR
TurboDoc.io leverages both OCR and ICR technology to deliver a seamless, intelligent document automation experience. Whether you need to extract data from a scanned invoice or digitize handwritten forms, TurboDoc’s integrated OCR/ICR software adapts to your content — improving accuracy and reducing manual effort across the entire document management pipeline.
Automate document processing with TurboDoc
Recognize invoices, contracts, and forms in seconds. No manual work or errors.
Try for free!
This hybrid approach enables organizations to scale their intelligent document processing without worrying about input type or format.
How OCR and ICR Work Together in Modern Workflows
In modern document processing workflows, OCR and ICR technologies no longer compete — they work together. While OCR excels at turning printed text into digital data, ICR is better suited for extracting handwritten information. Combining both enables full automation across various document types and formats.
Here’s how the flow typically works:
- Scanning – A document is digitized using a scanner or camera.
- OCR stage – The system first applies OCR technology to identify and convert printed sections.
- ICR stage – If OCR cannot interpret a field (e.g. handwriting), ICR adapts and processes that part using AI.
- Validation & export – Parsed data is structured and passed into the document management system or database.
Unlike traditional OCR-only systems, modern OCR and ICR software solutions offer intelligent document processing — reducing manual review and increasing accuracy. This hybrid model is especially useful in form processing, where one document may contain both typed and handwritten fields.
At TurboDoc.io, we implement this dual-stage approach to streamline document processing from scan to storage. Our platform automatically detects content type, applies the right engine (OCR or ICR), and feeds clean data into your business systems — all within one intelligent document processing solution.
Beyond OCR and ICR: Introducing OMR and Scan-and-Go Tech
While OCR and ICR are essential for converting printed and handwritten text into digital formats, OMR (Optical Mark Recognition) adds another layer to the document processing pipeline. OMR doesn’t read text — it detects marks (like checkboxes or bubbles), commonly used in tests, surveys, and ballots.
What’s the Difference: OCR vs ICR vs OMR?
OMR technology excels where OCR cannot — especially in fast form processing for standardized layouts. And unlike OCR, OMR doesn’t depend on language or font — only on the presence of a mark.
What is Scan-and-Go Technology?
Scan-and-Go tech, used in retail and logistics, combines barcode scanning, OCR, and sometimes ICR to automate data capture without manual input. These systems streamline tasks like shelf labeling, package tracking, and self-checkout — with real-time accuracy.
Integrated Recognition in Modern Workflows
In complex workflows, a single document or task may involve all three technologies:
- OCR processes printed text.
- ICR converts handwritten fields.
- OMR captures selected options or marks.
At TurboDoc.io, our platform supports OCR, ICR, and OMR within a unified environment — allowing users to handle entire document processing needs efficiently. Whether you’re digitizing contracts, analyzing surveys, or automating logistics forms, TurboDoc ensures accuracy, speed, and scalability.
Automate document processing with TurboDoc
Recognize invoices, contracts, and forms in seconds. No manual work or errors.
Try for free!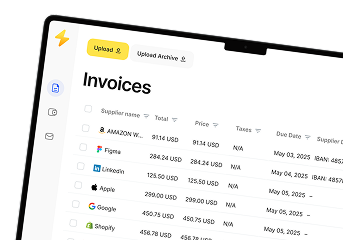
Common Errors in Recognition — and How to Prevent Them
Even modern OCR and ICR systems can struggle with real-world documents. Understanding the common recognition errors helps you choose the right tools — and avoid costly mistakes in your document processing workflow.
Typical OCR Errors
Traditional OCR technology is designed to read printed text, but it can fail when dealing with:
- Blurry or low-resolution scans
- Unusual fonts or formatting
- Artifacts such as smudges, lines, or folds
- Complex layouts with mixed content types
Though OCR works best with clean, high-contrast documents, its performance drops sharply on degraded images or non-standard typefaces.
Typical ICR Errors
ICR is an advanced form of recognition that depends on AI to read handwritten text. Still, it may struggle with:
- Messy or cursive handwriting
- Inconsistent spacing or alignment
- Poorly structured forms
ICR technologies address many of these with machine learning, but they still require well-prepared input to reach optimal accuracy and efficiency.
How TurboDoc.io Reduces Recognition Errors
At TurboDoc.io, we’ve built smart error prevention into our OCR/ICR software:
- Image preprocessing (e.g., noise reduction, skew correction)
- Custom templates for recurring document types
- Auto-correction modules trained on your previous data
- Integrated quality checks to flag ambiguous outputs
These features allow TurboDoc to adapt to different documents, whether scanned invoices, medical records, or handwritten forms — improving results far beyond traditional OCR technology.
Best Practices to Improve Input Quality
To maximize recognition accuracy across OCR and ICR systems, follow these simple tips:
- Use high-resolution scans (300 DPI or higher)
- Avoid shadows, folds, or heavy compression
- Standardize form layouts where possible
- Use black ink and capital letters in handwritten fields
By combining smart software and good scanning practices, you can eliminate most recognition issues — and streamline the entire document management workflow.
Future Trends in OCR/ICR Technology
As document processing grows more complex, OCR and ICR technologies are evolving to meet new demands. The future lies in greater flexibility, speed, and intelligence.
- AI-Powered ICR: Modern ICR now uses deep learning—especially CNNs and Transformers—to better interpret diverse handwriting styles, even with irregular formatting. These models improve over time, adapting to various document fonts and layouts.
- Mobile Handwriting Input: ICR is becoming faster and more lightweight, allowing handwritten input to be captured and recognized directly on mobile devices—without the need for scanning. This enables real-time data entry in retail, logistics, and healthcare.
- Real-Time Recognition: A growing trend is live recognition without saving files. Data is processed instantly from camera or device input, streamlining workflows and reducing manual delays.
Choosing OCR/ICR Software: What to Look For
Selecting the right OCR or ICR software depends on your specific document processing needs. Here are key factors to consider:
✅ Accuracy & Speed
Modern OCR systems should process printed text quickly and reliably. For handwritten content, ICR is designed to adapt—but may vary in accuracy depending on the handwriting styles and training data.
🔄 Learning Capabilities
Unlike traditional OCR, advanced ICR technologies may include machine learning models that improve over time. This is especially useful for complex documents or varying input formats.
🔗 API & Integration
Good document management software must support integration. Look for systems with strong APIs, allowing you to embed OCR/ICR functionality into your workflows—whether for real-time form processing or batch recognition.
🧩 User Interface & Workflow Support
Whether you’re handling invoices, forms, or scanned books, the platform should offer an intuitive interface and tools to manage the entire document workflow—from capture to data export.
The choice between OCR and ICR isn’t always binary—many modern solutions combine both to handle different types of content efficiently. Evaluate how each tool handles various document types, supports user corrections, and fits into your existing tech stack.
Conclusion: ICR, OCR and the Future of Document Recognition
When it comes to modern document processing, the choice isn’t OCR vs ICR, but how to use OCR and ICR together to achieve the best results. While OCR handles printed text efficiently, ICR goes further, reading complex handwritten input and adapting to varied document fonts and handwriting styles.
Understanding the differences between OCR vs ICR, along with the limitations of each, is key to choosing the right tool for your overall document management workflow. Whether you’re digitizing forms, automating invoices, or extracting data from mixed-format files, the right approach often combines both technologies.
Ready to streamline your document operations? Try TurboDoc.io or request a free demo to see how intelligent recognition software can transform your workflow.
Automate document processing with TurboDoc
Recognize invoices, contracts, and forms in seconds. No manual work or errors.
Try for free!
❓ FAQ
What is the difference between ICR and OCR?
ICR can read handwritten text using AI; OCR is best for printed text.
What does ICR stand for?
Intelligent Character Recognition.
What does the OCR stand for?
Optical Character Recognition.
What is the difference between OMR and OCR?
OMR detects marks (e.g., bubbles), while OCR reads printed characters.
What is scan and go technology OCR, OMR, ICR?
A hybrid tech used in self-service and logistics for fast document/data capture.
What is the full form of ICR test?
ICR Test = Intelligent Character Recognition Test, used to validate AI accuracy on handwriting.